In a more practical use case, could we ever stream video wirelessly under water?
Maybe you’ve seen something like this; it’s an underwater ROV that can take video and can be controlled by a user from above. It has to have a tether though, and not just so we don’t lose it. Electromagnetic waves attenuate quickly under water, which means our high bandwidth methods of communicating won’t work. If you want to send a lot of data quickly, you have to use a tether.
But what if we used ultrasonic communication?
You do see ultrasonic communication used occasionally with divers who want to communicate with the surface, but you never see video sent through these streams because it’s simply too low of bandwidth. To stream a compressed 720p video takes around a 5 mbps connection, standard definition takes around 3 mpbs. In the past I’ve written communication protocols using ultrasonic sound, however I’m going to use an actual product this time. At this site a nice communication device gets 62.5kbit/s, which is about 7.8125kbps (where kbps is bytes) and has a total range of about 300 m. I’ll be using this as a maximum theoretical.
The question I'm trying to answer is could I communicate a reasonably definition with good frame rates in real time off of an ultrasonic connection? Could we communicate video over just a couple kbps
Notice - one thing I’m not accounting for is computation; in this thought experiment we have unlimited computational power on each end, and as you’ll see the solution I come up with isn’t particularly easy to do.
Range and Latency
So range and latency are certainly the easiest things to compute so I figured I’d start here.
We know the speed of sound in air is 343m/s, but luckily in water it’s much faster, 1450m/s. If you’ve ever tried to stream a game from an EC2 instance you also may know that a goading is around 20ms, but up to 40 or 60ms is doable as well. So rearranging the velocity equation you get a range of 43.5 meters.
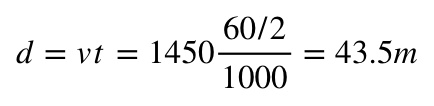
This isn’t particularly great range, I’ll admit, but it’s good enough. I can’t imagine you’ll be going farther than half a football field away for recreational uses.
Other compression options
There are also a few other compression options we could consider. I’m not going to use them (honestly partly because this is a thought experiment and I want to do something slightly different), but also because they might not work well in this circumstance.
Something like a huffman tree wouldn’t work because we’d have to send the tree over for every image, and on a gray style image most colors will end up being used anyways, sort of negating the point.
Also tracking pixels and only updating the ones that change, however that won’t work well in our use case since the rov would be moving, and almost no pixels would be staying in place. It also wouldn’t promise any sort of compression ratio, which is what we’re looking for.
Row-wise lossless compression would actually probably work well, and if you made it lossy I bet it’d be pretty ok in this situation. That said I want to try to get a better compression ratio, so I won’t use it.
Streaming quality
There are a number of practical measures we need to get out of the way first. Normally when you have video or an image you’d store it as a BGR triplet, where maybe each color is a byte (char) or float and sometimes there’s a fourth alpha channel. I’m not going to do that. Partly because I don’t think it’d be necessary when driving your submersible around, but also because it’d complicate the math unnecessarily. I’m going to use a gray style format, where each color is represented by a single byte. I think there are a lot of interesting things you could do with this but I’m just going to leave it as a one byte gray style image for now.
But let’s look at the numbers.
Here are some standard definitions, and with this we can calculate their bandwidth
| Definition | Name | Width | Height | Pixels (per img) | Required Bandwidth (30fps) |
| 240p | Potato quality | 320 | 240 | 76.8k | 2.304M |
| 360p | 480 | 360 | 172.8k | 5.184M | |
| 480p | SD | 640 | 480 | 411.84k | 12.355M |
| 720p | HD | 1280 | 720 | 921.6k | 27.65M |
| 1080 | HD | 1920 | 1080 | 2.073M | |
| 2160 | 2k | 3860 | 2160 | 8.337M |
As you can see it gets really expensive really fast if we don’t compress anything. So if I want communicate 480p video over ultrasonic communication, I’ll have to reduce it by an average factor of 1582, and if I drop the frame rate to 15fps it’ll have to go down by around 740.
If we use our 7.8kbps bandwidth as a benchmark, we get this table
| Frames per second | Bytes per image available |
| 1 | 7800 |
| 5 | 1560 |
| 15 | 520 |
| 20 | 390 |
| 30 | 260 |
So We'll want to see how few pixels per image we can get, allowing us to utilize higher framerates.
How we'll do it
So what I’m thinking is just to create some method to drop most unnecessary pixels and interpolate the rest of the data. Commonly what people will do to fill missing pixels is they’ll use a median blur filter, which uses a kernel to get the median pixel value and replace it.

Using a technique sort of like this, I hope to remove enough pixels to get us down to the required bandwidth. But this brings us to a number of problems. First off a median blur can only be used to replace at most 16% of the pixels with blank points of data confidently. We need to replace a lot more then that, and additionally we’d need to have a pre-defined area of where to drop pixels and where to keep them.
One thing we can try though is a mean square. So imagine I have a template that just randomly picked 3% of pixels in an image and saved them, and then we had that same template on the other side, which would tell us where to put the pixels. Intuitively this might be implemented like this

Where each side has an identical hash table for accessing this template, and the key is used to access the pre-determined table. We could use mean square to guess what value of pixel to use in each spot based on what’s in the window around it. A mean square algorithm for calculating value intensity might look like this
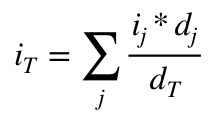
A better example that specifices where on the cordinate plane we are might be this:
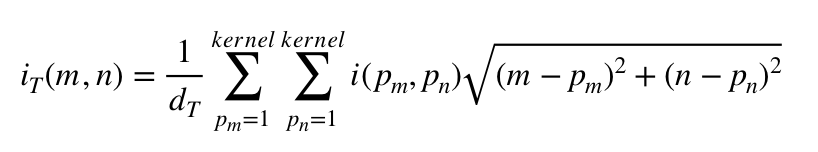
I created an image that randomly selected 20k pixels out of the 668668 total pixels (2.99%), saved those pixels, and then reconstructed it using a mean square average. In this case I progressively increased the kernel size, going 3, 5, and 13. This is the result.

Obviously the image on the right is extremely soft however it’s certainly useable if you were just using it to control an underwater drone. This would still require a 400kbps connection to communicate at 20fps using a 1001x668 pixel ratio. This compression ratio could transfer a 480p video at 1fps, which is better but not great.
Also as you know I’m not considering time to compute this, however as you can imagine it’s quite high. There are a number of speedups I could make but I don’t think this would ever be fast enough to be feasible.
Just for fun let's see what happens if we drop it down to 1%, and set the kernels to 5, 7, and 17.

In my mind this is kind of neat, especially when you consider the only data transferred is the following (where the white dots are the pixels, black is null for the first image, and the reverse for the second).

Improving the predetermined pixel map
One of the key improvements to how we’ll reduce the video bandwidth is by finding out which areas are most important to communicate, and then focusing on those areas. The way I figured we’d do this is we’d have a set of pre determined maps, and then we’d compare these maps with a feature or edge detection algorithm, and the ones with the most overlap would be used.
Initially I had planned to use an SSIM function to compare the predetermined maps vs the edge detection results, however due to the randomness of the pixels this turned out to not recognize a nearby pixel as relevant. A better solution is to convolve a mean square algorithm over the image.
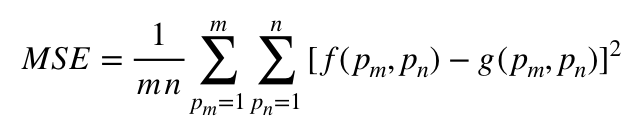
This iterates over each pixel computing a mean square algorithm to find the new pixel value. The best match is tracked, so after iterating through the the predetermined map with the lowest value will be chosen as the closest match.
Putting it together
So let’s say I wanted to communicate a 480p resolution at 2fps. This would mean I’d only be able to transfer 0.19% of the pixels to communicate with our deep sea ultrasonic sensor. Keeping this in mind, although this image isn’t scaled to 480p I will only transfer .19% of the pixels

Not bad, but still leaves something to be desired on the frames per second angle. Although technically drivable, it would be frustrating to look at a screen that only changes twice every second, although there isn't much we can do about it from a bandwidth perspective.
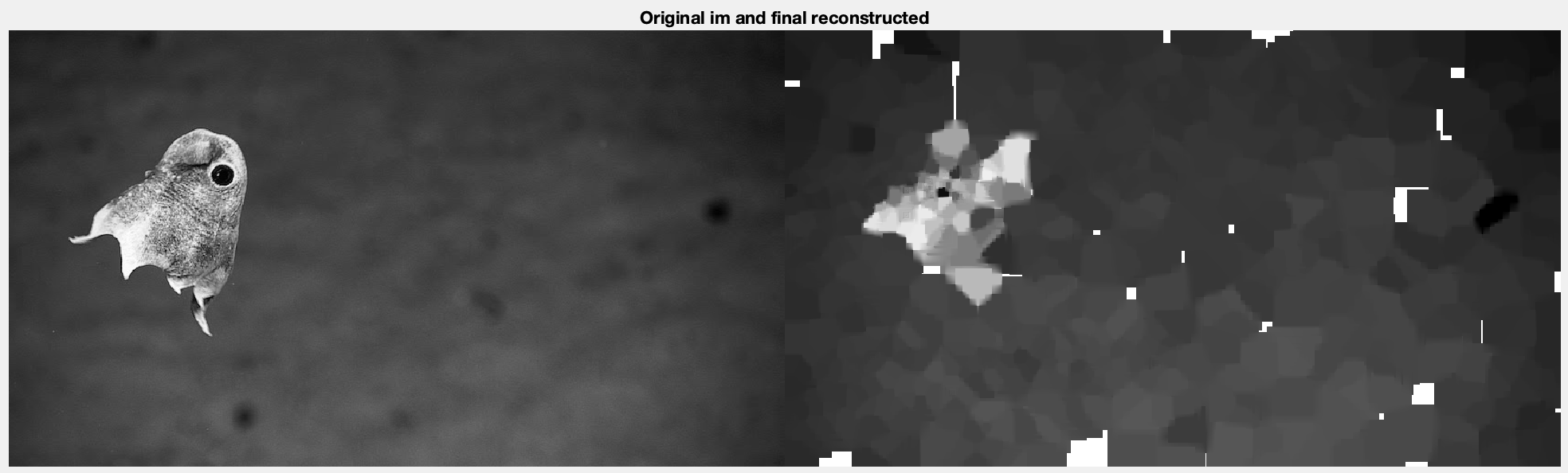
Let’s try an image that looks more like from a video stream. This is a random picture of a fish, where the resolution is 720p (1280,720). To communicate this at 5fps over a 7.8125kbps channel, we would need to make each picture 0.379% of it’s original size, which would mean we could only transfer 3497 pixels for each frame. Doing that produces this image.
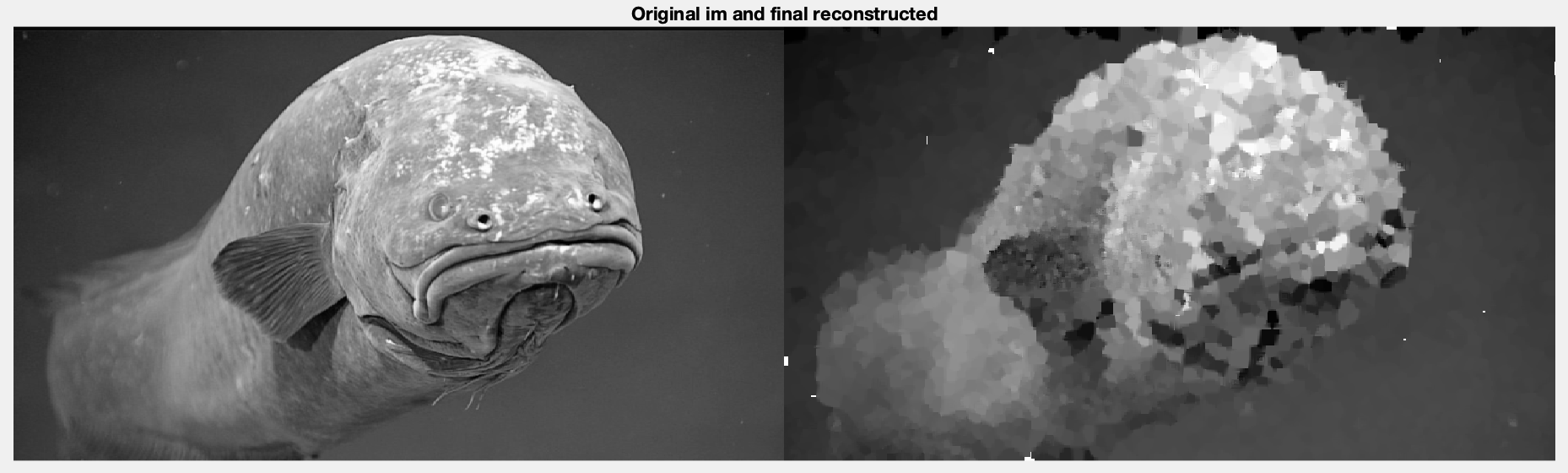
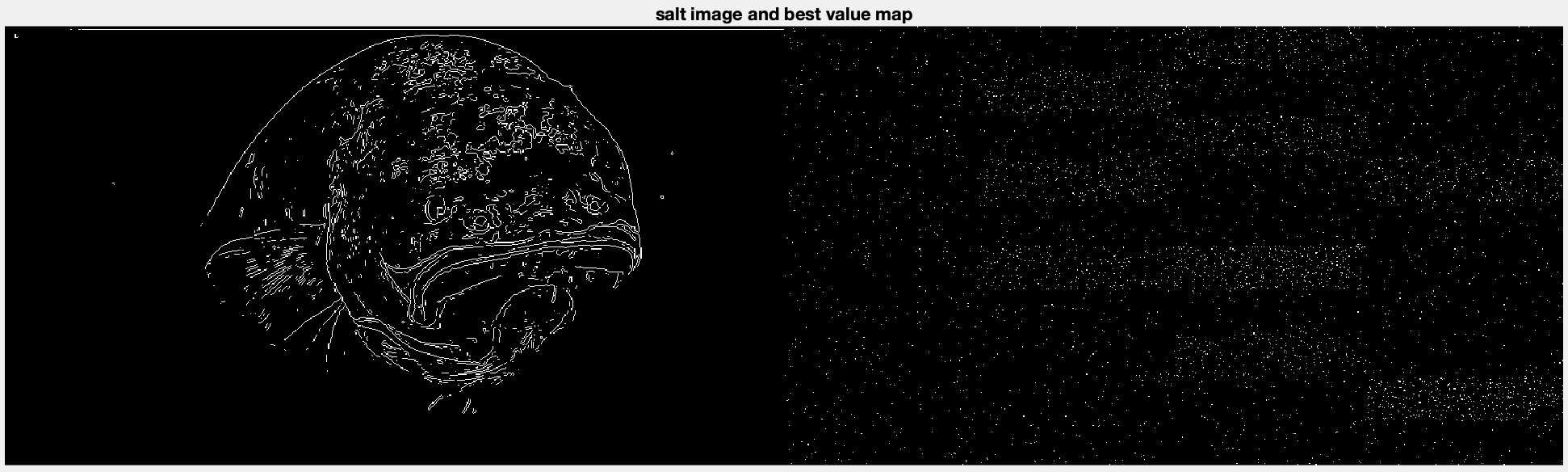
What we see is interesting. Basically the structure is all there, but a lot of the finer detail is missing since it was likely lost in the reconstruction. One thing that’s interesting though is we can look at the pre-determined map and Sobel image to see what portions of the image the processor decided to work on, and it shows us this

This is interesting because it suggests that the algorithm got caught up in trying to get data about the fin, which is why the face (what people might look at) is so blurry. One thing I was wondering was whether reducing the image size (scaling down to 480p) might produce a better image, since the Sobel algorithm might not pick up as many edges, and may not focus on it as much. I decided to reduce the image to 480p while leaving it at 5fps and reducing the kernel sizes.
This sort of worked. As we see, the algorithm focused on a much more broad scope, picking up more edges of the fish and less edges of their scale. Although you might have to zoon into the picture, you can see concentrations mostly around the fish head with a random concentration in the bottom right, likely due to a lack of a closer matching predetermined table. Another thing that might be helpful is tuning the Sobel algorithm to focus on greater changes, as to gather more of the edges of the fish and less edges from the fishes skin.
Lastly let’s look at one last pic, this one is the same as before (480p) but is more conducive to the algorithm, having less sharp features and more gradual edges, with a rather soft background and at 1fps.
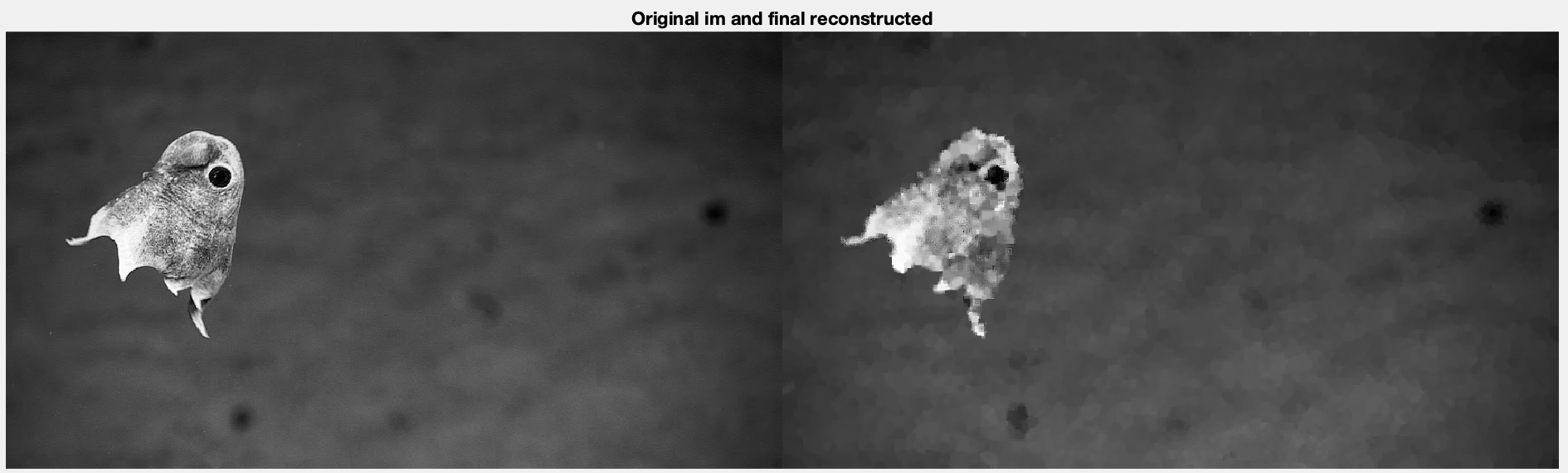
And as we can see, the background looks very similar and while the fish is softened, you can still see all of its distinctive features. In a video stream as it’s moving it would be harder to notice this, and this sort of stream would be received reasonably well with the exception fo the frame rate. The predetermined map lines up with what you'd expect as well.

And just for the sake of curiosity here's the image at 2fps
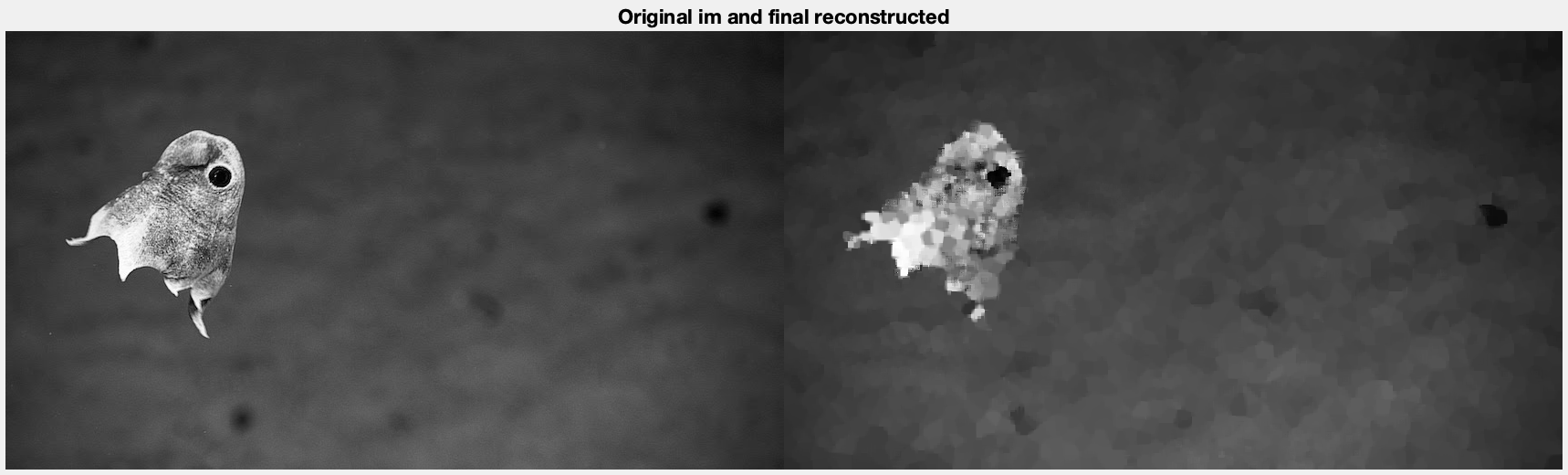
5fps

10fps

And 15fps
As we increase the fps the quality goes down, which is expected.
Overall
The two major downsides to this project are that it’s computationally slow, and that the resolution still isn’t that great, meaning it’s possible there’s a more traditional compression algorithm that could produce a similar image starting from a lower resolution image.
There are a number of improvements that could be made, as well. Most obviously is during some of the convolutions, I don’t modify the old value I recompute it each time. It’d clearly be much faster to optimize this however it wasn’t too big of a deal for testing purposes.
Two fundamental changes I’ve been thinking about is it’d be great to optimize our edge detection algorithm to focus on more important lines instead of fine details like scales or sand. There are also a number of other algorithms I could try to use when reconstructing the image, however I’m currently just using a modified mean square. Lastly though to some degree it only matters that the end user thinks what they’re seeing is high quality, so there are likely some sharpening algorithms I could try to implement, however that felt too superficial to try to implement here.
I’m not sure if you’d want to communicate video over ultrasonic channels to be honest. I never got near my fps goals, however this was certainly an interesting though experiment in my mind.
I’ll upload the code to github in a bit, I’ll likely put it at this repo or I’ll update the blog. Everything is written in Matlab and you’ll have to have OpenCV installed, which is part of the Image Processing toolbox.